本文共 7340 字,大约阅读时间需要 24 分钟。
Machine Learning
Machine Learning Onramp
2.1 Overview
输入数据 -> 组织与预处理数据 -> 探索性数据分析与特征提取 ->建立模型 -> 评估模型 -> 部署并使用模型
Import Data -> Organize and Preprocess Data -> Explore Data & Engineer Feature -> Build Model -> Evaluate Model -> Deploy Model for Use
2.2 Import Data
Task 1
手写字母作为单独的文本文件存储。每个文件均以逗号分隔,并包含四列:时间戳记,笔的水平位置,笔的垂直位置以及笔的压力。时间戳是自开始收集数据以来经过的毫秒数。其他变量以归一化单位(0到1)表示。对于笔位置,0代表书写表面的底部和左侧边缘,而1代表顶部和右侧边缘。
您可以使用readtable函数从电子表格或文本文件导入表格数据,并将结果存储为表格。
letter = readtable("J.txt"); 这将从电子表格myfile.xlsx导入数据,并将其存储在名为data的表中。
Task 2
您可以使用点表示法来引用表中的任何单个变量
X = letter.X;Y = letter.Y;plot(X,Y)
这将从表letter中提取变量X并将结果存储在名为X的新变量中。类似地,将变量Y提取到Y中,并使用plot()函数绘图。

默认轴限制会扭曲字母的纵横比。可以使用axis命令强制轴保留数据的纵横比。
axis equal
使用命令轴equal来校正绘图的纵横比。

经过矫正后,图片显示比例正常。
2.3 Process Data
Task 1
1.手写数据的笔位置以标准化单位(0到1)测量。然而,用于记录数据的平板电脑并不方正。这意味着1的垂直距离相当于10英寸,而相同的水平距离相当于15英寸。要更正此问题,应将水平单位调整为范围[0 1.5],而不是[0 1]。
将表格字母的X变量中的值乘以纵横比1.5。将结果重新分配回X,以便字母包含更正的数据。
letter.X = X * 1.5;
2.处理时间戳
将所有时间戳都减去第一个值,并且将其除以1000
letter.Time = (letter.Time - letter.Time(1)) / 1000
2.4.1 Extract Features
Task 1
提取一个信号持续的时间,从letter中提取最后一个Time值到dur中,即为该字母书写所用的时间。
dur = letter.Time(end)
Task 2
range()函数可以返回数组中值的范围,即range(X) = max(X) - min(X);
使用range函数通过将letter.Y的值范围除以letter.X的值范围来计算字母的长宽比。将结果分配给一个名为aratio的变量。
aratio = range(letter.Y) / range(letter.X)
2.4.2 Viewing Features
MAT文件featuredata.mat包含一个提取的功能表,该功能表提取了由各种人撰写的470个字母。表格功能具有三个变量:AspectRatio(长宽比)和Duration(时长)和Character(已知字母)。
load featuredata.matfeatures

scatter()可以用来描绘散点图,使用散点图功能绘制提取的特征,横轴为长宽比,纵轴为时长。
scatter(features.AspectRatio,features.Duration)

尚不清楚这些功能是否足以区分数据集中的三个字母(J,M和V)。 gscatter()函数可进行分组的散点图–即根据分组变量对点进行着色的散点图。
gscatter(features.AspectRatio,features.Duration,features.Character)

可以使用xlim()或ylin()置顶显示某一范围的xy值,用法如:
xlim([2,4])ylim([0,1])

2.5 Build a Model
Task 1
一个简单的模型是将观察结果与最接近的已知示例归为同一类。这称为k最近邻居(kNN)模型。您可以通过将数据表传递给fitcknn函数来拟合kNN模型。
470个已知示例的要素和类存储在表要素中,该要素存储在featuredata.mat中。
使用fitcknn函数将模型拟合到存储在要素中的数据。已知的类存储在名为Character的变量中。将结果模型存储在名为knnmodel的变量中。
knnmodel = fitcknn(features,"Character")
第一个输入是包含训练数据和目标字母的数据table,第二个输入是表中响应变量的名称(即希望模型预测的类)。输出是包含拟合模型的变量。

Task 2
使用predict()预测函数,确定新观测值的预测类别。
通常,新观察结果采用表格的形式,具有与用于训练模型相同的预测变量。但是,在这种情况下,模型使用两个数字功能(长宽比和持续时间),因此也可以将观察值提供为具有两列的数字数组。
predicted = predict(knnmodel,[4,1.2]) % 4和1.2分别对应AspectRatio和Duration两个值
predicted : V
Task 3
默认情况下,fitcknn拟合k = 1的kNN模型。也就是说,该模型仅使用单个最接近的已知示例对给定的观察进行分类。这使模型对训练数据中的任何异常值都敏感,例如图中突出显示的那些值。离群值附近的新观测值可能会被错误分类。

通过增加k的值(即使用几个邻居中最常见的类别),可以使模型对训练数据中的特定观测值不那么敏感。通常,这通常会改善模型的性能。但是,模型在任何特定测试集上的表现方式取决于该集中的特定观察结果。
修改fitcknn()函数中"NumNeighbors"的默认值,使其值为5,让模型对特定的观测值没那么敏感。
knnmodel = fitcknn(features,"Character","NumNeighbors",5)predicted = predict(knnmodel,[4,1.2])
predicted = V
Further Practice
可以使用两种NumNeighbors的设置,分别对模型进行预测,查看并比较不同NumNeighbors对预测结果的影响:
knnmodel1 = fitcknn(features,"Character") %NumNeighbor use its default valueknnmodel2 = fitcknn(features,"Character","NumNeighbors",5) %NumNeighbor have its own valuepredicted1 = predict(knnmodel1,[features.AspectRatio,features.Duration])predicted2 = predict(knnmodel2,[features.AspectRatio,features.Duration])correct1 = sum(predicted1 == features.Character) / numel(predicted1) %caculate correct ratecorrect2 = sum(predicted2 == features.Character) / numel(predicted2) %numel() can return the number of array
correct1 = 1correct2 = 0.929787
2.6 Evaluate the Model
Task 1
kNN模型有多好?您可以使用模型进行预测,但是这些预测的效果如何?通常,您希望通过让模型对您知道正确分类的观测值进行预测来测试模型。
文件featuredata.mat包含一个表testdata,该表的testdata具有与feature相同的变量,包括测试观察的已知类。但是,测试数据中的观察结果未包含在功能中。您可以使用预测功能为测试数据中的观测值确定kNN模型的预测,然后将预测与已知类进行比较,以查看模型在新数据上的表现如何。
请注意,根据模型进行预测时,预测函数将忽略Character变量。
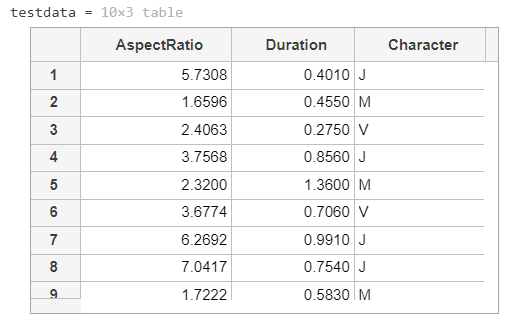
结合训练模型knnmodel使用预测功能对表testdata中的字母进行分类。将预测存储在称为预测的变量中。
load featuredata.matknnmodel = fitcknn(features,"Character","NumNeighbors",5); %data in features is used to train the modeltestdata%%%%%%%%%%predictions = predict(knnmodel,[testdata.AspectRatio,testdata.Duration])
iscorrect = predictions == testdata.Character %get correct table
accuracy = sum(iscorrect) / numel(testdata.Character) %caculate the correct rate
iswrong = predictions ~= testdata.Character %get wrong table attention, here is ~=misclassrate = sum(iswrong) / numel(testdata.Character)
Task 5
混淆矩阵通常通过根据元素的值着色来可视化。通常,对角线元素(正确的分类)以一种颜色着色,而其他元素(错误的分类)以另一种颜色着色。您可以使用confusionchart函数来可视化混淆矩阵。
confusionchart(ytrue,ypred);
其中ytrue是已知类的向量,而ypred是预测类的向量。
使用conchartchart函数将预测与已知标签进行比较。
confusionchart(testdata.Character,predictions)

图中可以看到,有4个J,3个M,1个V被成功分类,1个V被识别成J,1个M被识别成V
Further Practice
wrongdata = [testdata.AspectRatio,testdata.Duration] %Get data from unsuccessful classification letters
2.7 Review
Task 1
MAT文件featuredata13letters.mat包含一个具有与以前相同功能的表(功能)。但是,现在的数据包括13个不同字母的样本。
使用gscatter函数绘制要素中的观测值,横轴为长宽比,纵轴为持续时间,按类别着色(存储在Character变量中)。
load featuredata13letters.matfeaturestestdata%%%%%%%%%%gscatter(features.AspectRatio,features.Duration,features.Character)

knnmodel = fitcknn(features,"Character","NumNeighbors",5)predictions = predict(knnmodel,[testdata.AspectRatio,testdata.Duration])
misclass = predictions ~= testdata.Character
misclass = sum(predictions ~= testdata.Character) / numel(predictions)confusionchart(testdata.Character,predictions)
3.1 Organization of Data Files
3.2 Creating Datastores
Task 1
user003_B_2.txt 该文件将包含由名为“ user003”的志愿者撰写的字母B的第二个样本。
您可以使用通配符将数据存储到与特定模式匹配的文件或文件夹中。
ds = datastore(“data*.xlsx”); 手写数据文件的名称格式为user003_B_2.txt。
使用数据存储功能将数据存储到所有包含字母M的文件。这些文件的名称带有_M_,扩展名为.txt。将数据存储存储在名为letterds的变量中。
letterds = datastore("*_M_*") 将所有M字母通过datastore()函数,读入letterds变量。
Task 2
将letterds中的数据读入data。
第一次使用读取功能将从第一个文件导入数据。第二次使用它将从第二个文件导入数据,依此类推。
data = read(letterds)
Task 3
用plot()函数将data中的X与Y可视化。
plot(data.X,data.Y)

Task4
再次使用read()函数,读入第二个数据。
data = read(letterds)plot(data.X,data.Y)

Task 5
readall()函数将数据存储中所有文件中的数据导入单个变量中。
使用readall函数将所有文件中的数据导入到名为data的表中。通过对X绘制Y来可视化数据。
data = readall(letterds)plot(data.X,data.Y)

Further Practice
letterds = datastore("*_V_*") %读取所有的字母Vdata = readall(letterds)plot(data.X,data.Y) 
3.3 Adding a Data Transformation
通常,您将希望对原始数据的每个样本进行一系列预处理操作。自动执行此过程的第一步是制作一个自定义函数,该函数将应用您的特定预处理操作。
Task 1
在脚本末尾添加自定义函数。进行数据预处理,达到以下功能:
整理时间戳、将data.X乘1.5倍
在脚本的末尾创建一个称为scale的函数,该函数执行以下操作:
由于这些命令直接修改变量数据,因此您的函数应同时将数据用作输入和输出变量。
letterds = datastore("*_M_*.txt");data = read(letterds);data = scale(data);plot(data.X,data.Y)axis equalplot(data.Time,data.Y)ylabel("Vertical position")xlabel("Time")%%%%%%%%%%function data = scale(data) data.Time = (data.Time - data.Time(1)) / 1000 data.X = data.X * 1.5end Task 2
如果希望数据存储区在读取数据时应用此功能。您可以使用转换后的数据存储来执行此操作。
要将一个函数用作另一个函数的输入,请通过在函数名称的开头添加@符号来创建函数句柄。
transform(ds,@myfun)
函数句柄是对函数的引用。如果没有@符号,MATLAB会将函数名称解释为对该函数的调用。
使用转换功能来创建一个称为preprocds的转换后的数据存储。此数据存储区应将缩放功能应用于字母所引用的数据。
preprocds = transform(letterds,@scale)
可以将所有存于letterds中的数据都通过scale函数进行预处理。
Task 3
data = readall(preprocds);plot(data.Time,data.Y)
Task 4
改良scale()函数,增加一个功能:
从两个分量中减去平均位置:
function data = scale(data) data.Time = (data.Time - data.Time(1)) / 1000 data.X = data.X * 1.5 data.X = data.X - mean(data.X); % mean()计算均值 data.Y = data.Y - mean(data.Y);end
请注意,这将带来一个问题,使绘图显示为空白。您将在下一个任务中解决此问题。
Task 5
**涉及NaN的任何计算(包括对平均值的函数的默认使用)都将导致NaN。**这在机器学习中很重要,因为在机器学习中,数据经常缺少值。在手写数据中,书写者将笔从数位板上提起的任何地方都会出现NaN。
您可以使用"omitnan"选项具有统计功能,例如均值忽略缺失值。
function data = scale(data) data.Time = (data.Time - data.Time(1)) / 1000 data.X = data.X * 1.5 data.X = data.X - mean(data.X,"omitnan"); % mean()计算均值,使用omitnan忽略为NaN的值 data.Y = data.Y - mean(data.Y,"omitnan");end
转载地址:http://wjugf.baihongyu.com/